Implementing Active Ranking
A core task in social choice is the allocation of fixed resources among a set of items: funding across projects, budget across priorities, prize money across submissions. The output are weights – percentages out of 100 which say how valuable each item is relative to the others.
A common approach – asking people to score items on a scale, and then taking some sort of average – is fast but unreliable. Scores are subjective and uncalibrated: one person’s 7 is another person’s 4. Legitimacy suffers.
Pairwise comparison sidesteps this by asking a simpler question: “Which of these two do you prefer, and (optionally) by how much?” The cognitive load per judgment is lower, the signal is cleaner, and the results can be converted into weights that reflect genuine collective preference – from which rankings, allocations, and funding decisions all follow.
The problem is cost. Pairwise comparison scales quadratically: \(k\) items means \(k(k-1)/2\) possible pairs which need deciding. Active ranking – choosing which pairs to show based on what the system already knows, significantly reducing the number of pairs you most observe – is key to making pairwise methods practical.
This essay will explore how active ranking worked in practice – over three weeks in February and March 2026, during a live game jam – as part of PowerRanker, a spectral ranking engine that turns pairwise preferences into distributions of weights over items.
This essay was drafted by Claude using git commit logs and edited for style and flow.
I. Background
Since joining the Cartridge Gaming Company a little less than a year ago, one of my responsibilities has been running their quarterly hackathons. In preparation for their eighth jam, I saw an opportunity to put the ideas from The Pairwise Paradigm into practice – not just active ranking, but the full end-to-end pipeline: interface design, data encoding, and algorithmic pair selection. By bringing pairwise judging into the game jam process, we could distribute the judging burden across the ecosystem, producing more legitimate results with less per-juror effort.
The result was a homespun judging tool called Daimyo. Judges would see two submissions side by side – each with an AI-generated summary, playable links, and structured metrics – and were asked a single question: “Which is the stronger game jam entry?”
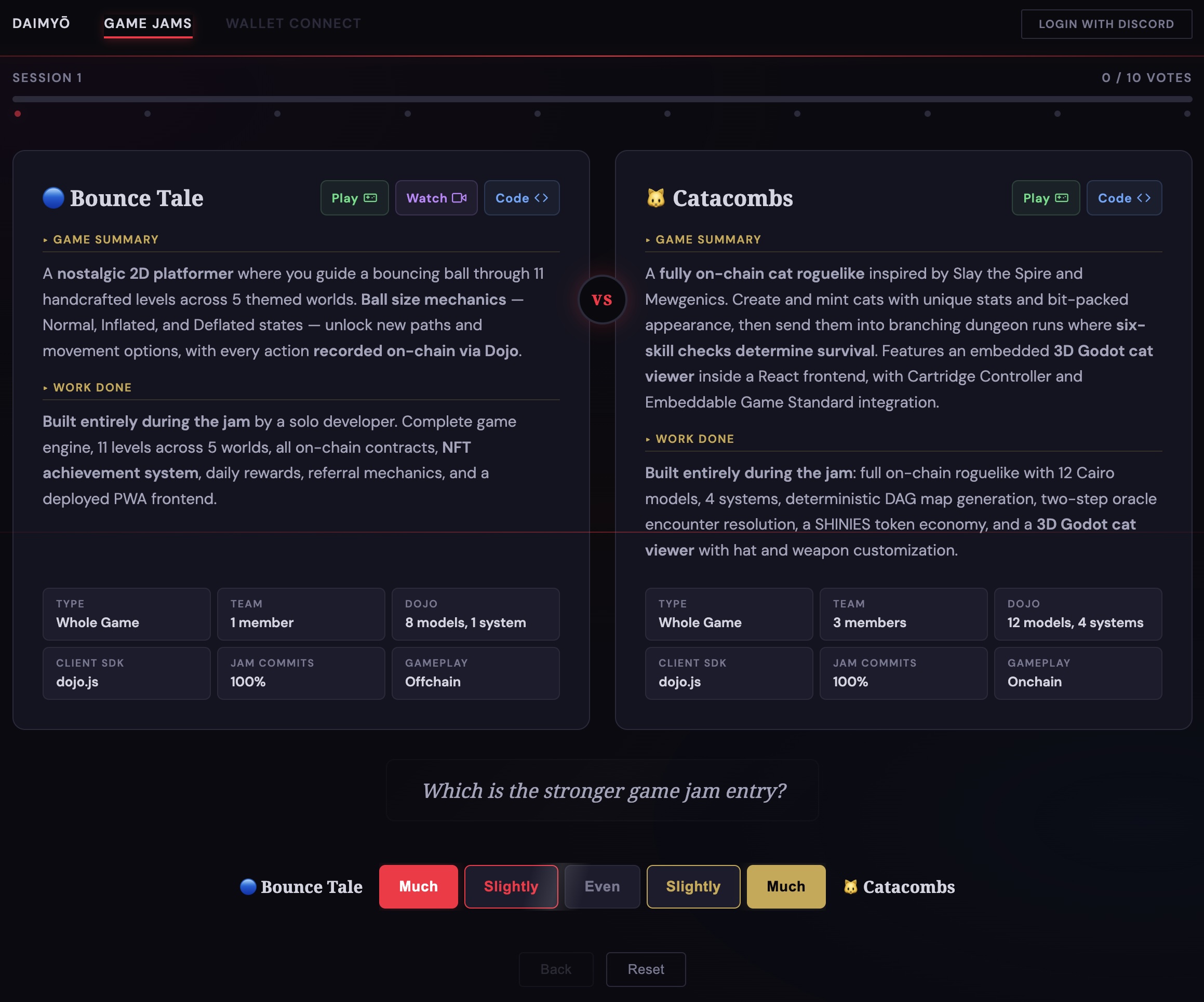
Responses used a five-point Likert scale (Much / Slightly / Even / Slightly / Much), which we encoded as values from 0 to 1 in increments of 0.25. Each judgment was designed to take about 30 seconds, and judges were asked for 10 comparisons per session, keeping the total time commitment at about five minutes. PowerRanker then aggregated these comparisons into a collective weighting, used to decide winners and give out prizes.
The initiative was successful – judges enjoyed encountering the projects in this way, the process made the game jam more visible to the larger ecosystem, and we were able to produce good results with a relatively small voter lift.
Of the ideas from The Pairwise Paradigm, active ranking was the one that advanced the most during this process. The original proposal was simple: for every pair \((a, b)\), construct a Beta distribution from the vote counts and sample pairs proportional to \(\text{Var}(p_{ab})\). An optional extension would weight by \(\text{Var}(p_{ab}) \cdot w_a \cdot w_b\), upsampling uncertain pairs between high-value items. In theory, this would reduce the data requirement from \(O(k^2)\) to some multiple of \(k\), a fundamental change in complexity.
This was the plan. It did not work as intended.
II. Variance-Based Selection
The initial implementation followed the original proposal: Beta-variance-weighted sampling without replacement, with an optional impact flag that multiplied variance by the product of both items’ current weights.
Watching it run against real data, however, two problems became clear.
Variance sampling did explore the pair space – unobserved pairs have a higher variance under a Beta prior, so the system naturally surfaced unseen comparisons. But it explored indiscriminately, without regard to relative ordering. The system would spend votes resolving the bear-vs-rabbit comparison with the same urgency as bear-vs-lion, even though these comparisons are not equally important for discovering the final ordering. Variance told us what we hadn’t seen, but not what we needed to see.
The weight-scaling extension – multiplying variance by \(w_a \cdot w_b\) – introduced a different problem: path dependence. With sparse early data, the ranking engine produces extreme weights – an item that wins its first two comparisons can briefly appear to dominate the entire set. Sampling based on these volatile early weights meant that early winners were shown more often, producing more data about them and reinforcing their high weights – a classic “rich get richer” problem.
Clearly, variance wasn’t it.
III. Composable Transforms
Before abandoning variance, we tried to save it. The first iteration added a coverage term alongside variance. Coverage tracked how many times each item had been observed in any comparison, and penalized well-observed items: \(\frac{1}{1 + n/N}\) initially, then \(\frac{1}{\sqrt{1 + n}}\) for faster drop-off.
The idea was to balance exploitation (compare uncertain pairs) with exploration (compare unseen items). We also modified the weight term, compressing it via sqrt to keep it in range with the other factors (\(\sqrt(w_a \cdot w_b)\)). The goal was to observe all items a few times, and then concentrate observations on similarly-ranked items, as well as the top-weighted items, directing attention to where it had the highest impact.
The selection function was multiplicitive, with each term contributing proportionally and toggled individually: sampleWeight = variance * weight * coverage.
This was better. Items that had been ignored were surfaced, and attention was distributed more evenly and efficiently across the set. But the weight component still created path dependence, and the interaction between three multiplicative terms (variance, coverage, weight) was hard to reason about.
We were making progress, but the deeper problem remained: variance is fundamentally order-agnostic. The early intuition – that variance-based sampling could reduce the data requirement by an entire complexity class – was wrong.
IV. The Pivot
We eventually abandoned variance and weight-based selection entirely. In order to reduce ranking to \(O(n)\) comparisons, the selection signal needed to be grounded in concrete ordinal positions instead of global statistical notions of confidence. The earlier intuition – selecting pairs based on some notion of uncertainty-reduction – was right, but the approach had been wrong.
The replacement was activeSelect(), built on three multiplicative terms, which as before could be toggled on and off individually.
pos is determined from current data – weights are produced internally and used to create an ordering, from which further statistics were derived:
- Coverage: \(\frac{1}{\sqrt{1 + n_a}} \cdot \frac{1}{\sqrt{1 + n_b}}\) – favors items with fewer observations
- Proximity: \(\frac{1}{1 + \lvert pos_a - pos_b \rvert}\) – favors items close together in the current ranking
- Position: \(\frac{1}{\sqrt{pos_a \cdot pos_b}}\) – favors items near the top
Coverage was kept from the earlier iteration.
Proximity and position were new – ordinal variants of the earlier variance and weight terms.
The proximity term became the main engine of active selection. Consider: a weighting of \(n\) items has \(n-1\) degrees of freedom – the ratios between consecutive items. The goal of the pairwise process, then, should be to achieve high confidence on the relationship between each item and its neighbors.
“Neighbor” should be understood probabilistically – two or three comparisons with items one or two positions away, one or two comparisons with items three or four positions away, etc.
Early on, the graph is sparse and the ranking is fuzzy, so coverage dominates: every item needs a few comparisons to anchor its position. As data accumulates, proximity dominates, concentrating attention on the boundaries where precision is useful. Position adds an optional bias toward observing pairs towards the top of the ranking, where larger weights call for higher precision.
This new approach was coherent and intuitive in a way that the previous one was not.
V. Tuning
The new design required its own round of tuning, but the iterations were faster and more principled because the terms were independently interpretable. Claude could perform fast simulations, letting us explore the behavior of different parameterizations interactively.
Range matching. A subtlety of multiplicative composition is that all terms need to operate on similar scales. If one term ranges from 0.00001 to 0.99999 while the others range from 0.2 to 0.6, the wide-range term dominates the outcome. Getting the terms into comparable ranges was a recurring concern throughout tuning, leading to several backs-and-forth around squaring and rooting.
Regularization. The first version had no way to soften the weighting.
In production, under-observed entries were getting starved while already-ranked items dominated.
We added a regularization parameter r (0 = uniform, 1 = full weighting), which let us mitigate path-dependent effects.
The initial implementation was a linear blend: \(r \cdot w + (1 - r)\). This didn’t work: the blend collapsed signal, producing useless values like 0.500001. We replaced the linear blend with a power transform: \(w^r\), spanning the same range while preserving signal.
Coverage formula. The coverage term oscillated between \(\frac{1}{1+n}\) and \(\frac{1}{\sqrt{1+n}}\) as we ran simulations and explored alternative paramaterizations. The sqrt form was chosen for its gentler drop-off, allowing items with 3-4 observations to continue to appear while still favoring items with zero observations.
Term composition. Initially, we chose pairs using all three terms, but decided mid-judging to drop the position term and use coverage and proximity only with r=0.9.
This made helped distribute voter attention across the entire set of items, increasing legitimacy.
This decision reveals an important subtlety in social choice: perceived legitimacy of a process just is as important as how close the final weights may come to an abstract ideal.
VI. Validation
After the design stabilized, we ran simulations to validate the approach. We generated items with known power-law weights, simulated judges making noisy Bradley-Terry comparisons, and measured how well the ranking engine recovered the true ordering.
The simulation also clarified a foundational question about the ranking engine itself: whether preferences should be encoded as unidirectional (0.75 to A) or bidirectional (0.75 to A, 0.25 to B). With Likert-binned vote strengths, unidirectional preferences produce unbounded weight ratios – the top item’s weight grows limitlessly relative to the bottom, as preference “mass” accumulated unevenly.
Bidirectional preferences, by contrast, cause weights to converge, as every comparison contributes balanced information. This insight was helpful for understanding “convergence” in this context – and is a jumping off point for future research.
Our independent variable was votes per item (vpi): the total number of votes divided by the total number of items. Simulation results showed that with active selection, Spearman rank correlation reaches 0.95+ at around 10-12 vpi for most distributions.
The simulation helped balance the relative weighting of the three terms, confirming that the range-matching intuition from manual tuning was correct. It also gave us confidence in the votes-per-item target, by showing that an accurate ordering can be reliably recovered within our vote budget, and let us publicize the results with confidence.
For a set of 30 items, 10 vpi means 300 total votes, or 15 judges each making 20 comparisons. At 30 seconds per comparison, that’s 10 minutes per judge. This is identical to The Pairwise Paradigm’s \(10k\) estimate, although achieved through a different mechanism than originally proposed.
In the case of the game jam, we received 360 votes from 16 judges. This was enough to produce rankings that were seen as legitimate and reflective of actual submission quality.
VII. Reflections
Theory vs practice.
The variance-based approach made sense on paper. It was information-theoretically motivated, computationally efficient, and had a clear connection to the existing literature. But it failed in practice because it treated pairs as isolated statistical objects rather than as part of a unified ranking structure. The position-aware model succeeded because it grounded the selection process in the ranking it was trying to refine.
Composability matters.
The ability to drop or add terms based on context proved valuable in both development and production. A single monolithic scoring function would have been harder to adapt.
The weights weren’t ready for prime time.
We had initially hoped to distribute prize money directly using the output weights – the highest-leverage use of the PowerRanker technique. In the end, however, we didn’t feel confident enough in the weight precision to tie dollars to them, especially as the selection process itself evolved over the course of vote-gathering. The ranking was reliable, but the weights need more work before they could be financially load-bearing.
Open questions remain.
The first iteration of Daimyo validated many of the ideas put forward in The Pairwise Paradigm, specifically around the design of the UI and the ability of active ranking to reduce the voting requirement. Future research should push the simulations further, showing specifically under what circumstances different paramaterizations can achieve desired outcomes.
This research, like the earlier work on pseudocounts, was conducted in collaboration with Claude – both the R&D itself and the writing of this essay. The pattern was similar: rapid iteration through a search space, punctuated by moments where stepping back and questioning assumptions.